Abstract
Parameter-efficient transfer learning (PETL) methods show promise in adapting a pre-trained model to various downstream tasks while training only a few parameters. In the computer vision (CV) domain, numerous PETL algorithms have been proposed, but their direct employment or comparison remains inconvenient. To address this challenge, we construct a Unified Visual PETL Benchmark (V-PETL Bench) for the CV domain by selecting 30 diverse, challenging, and comprehensive datasets from image recognition, video action recognition, and dense prediction tasks. On these datasets, we systematically evaluate 25 dominant PETL algorithms and open-source a modular and extensible codebase for fair evaluation of these algorithms. V-PETL Bench runs on NVIDIA A800 GPUs and requires approximately 310 GPU days . We release all the checkpoints and training logs, making it more efficient and friendly to researchers. Additionally, V-PETL Bench will be continuously updated for new PETL algorithms and CV tasks.
PETL Algorithms
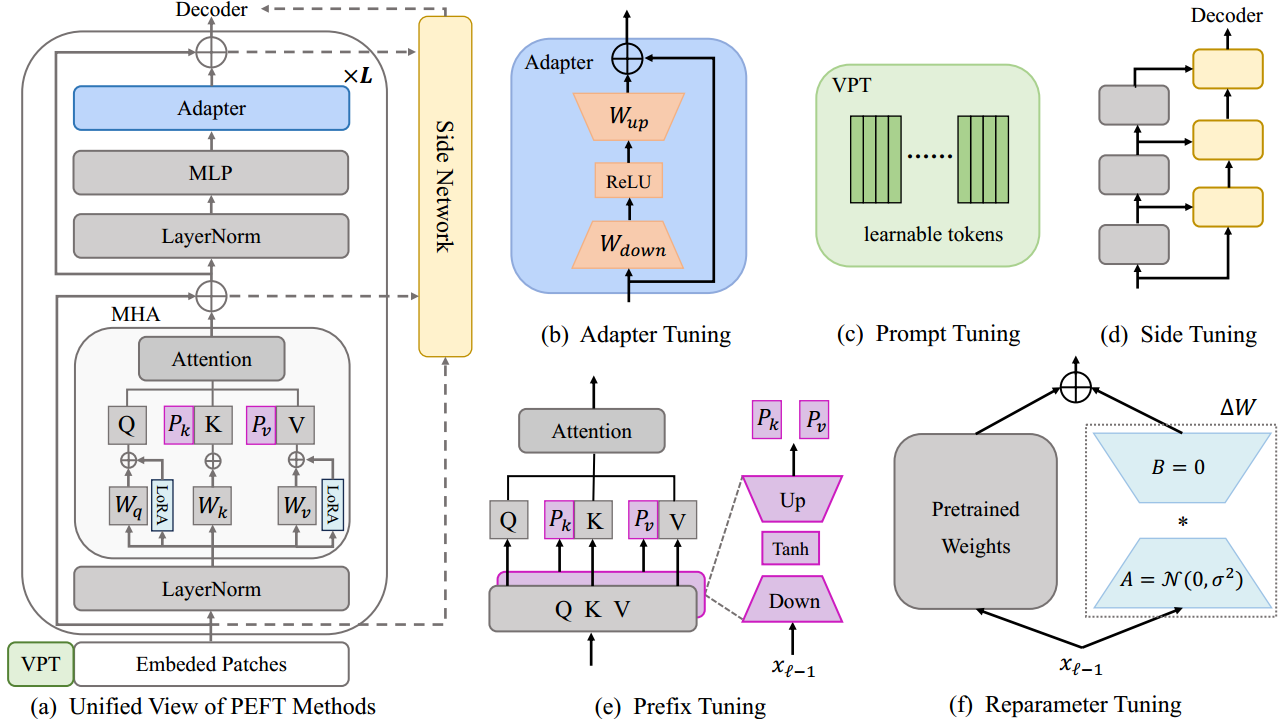
In visual PETL survey, existing PETL methods can be divided into 7 basic categories. For each category, we select multiple algorithms for implementation within the V-PETL Bench. We implement 2 traditional and 25 PETL algorithms in the codebase for V-PETL Bench,including Full fine-tuning, Frozen, Adapter, AdaptFormer, SCT, BitFit, U-Tuning, VPT-shallow, VPT-Deep, Prefix Tuning, SSF, LoRA, NOAHFacT, RepAdapter, Hydra, LST, DTL, HST, GPS, LAST, SNF, BAPAT, LNTUNE, LoRand, E3VA, and Mona. The algorithms are chosen based on the following considerations: 1) The algorithm is commonly used in the visual PETL domain and has considerable influence; 2) The algorithm corresponds with the comprehensive timeline of visual PETL development.
Tasks and Datasets
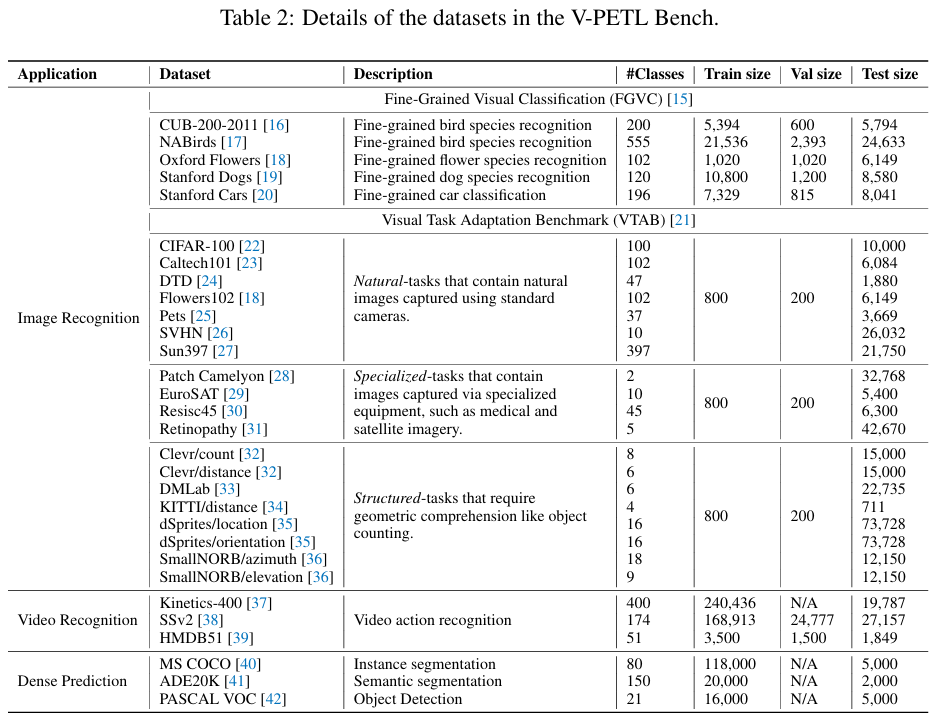
The V-PETL Bench includes 30 datasets from image recognition, video action recognition, and dense prediction tasks. Each dataset in the V-PETL Bench is under a permissive license that allows usage for research purposes. These datasets are chosen based on the following considerations: 1) The dataset represents a mainstream CV task and is broadly relevant to PETL; 2) The dataset is diverse and covers multiple domains; 3) The training process is environmentally sustainable and affordable for research labs in both industry and academia.
Performance-Parameter Trade-off Metric
For the evaluation of PETL algorithms, to compare different methods with a single number that considers both task performance and parameter-efficiency, we define the Performance-Parameter Trade-off (PPT) metric. C is a normalization constant set at 10^7, aligns with the typical parameter sizes of existing PETL algorithms.
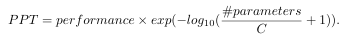
Benchmark and Evaluations
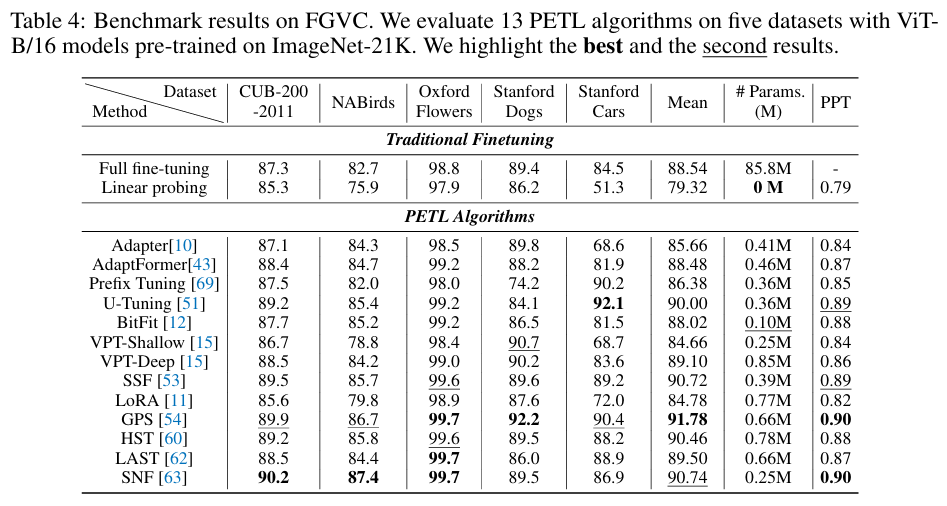
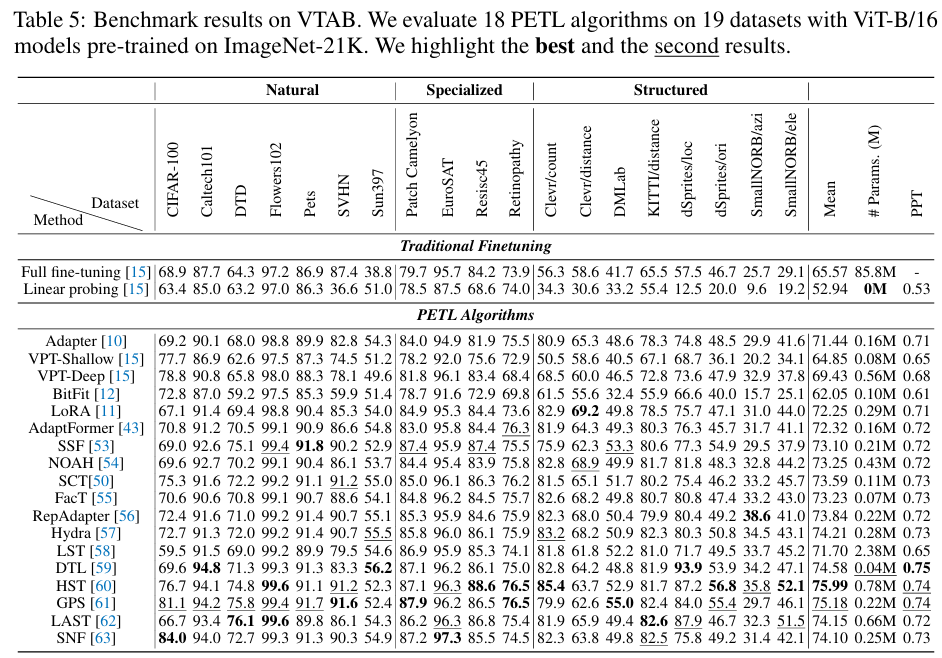
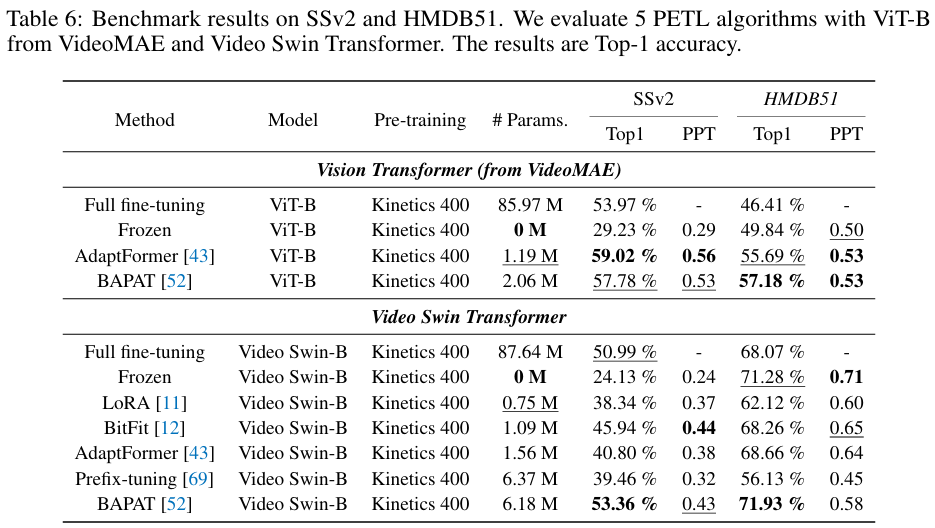
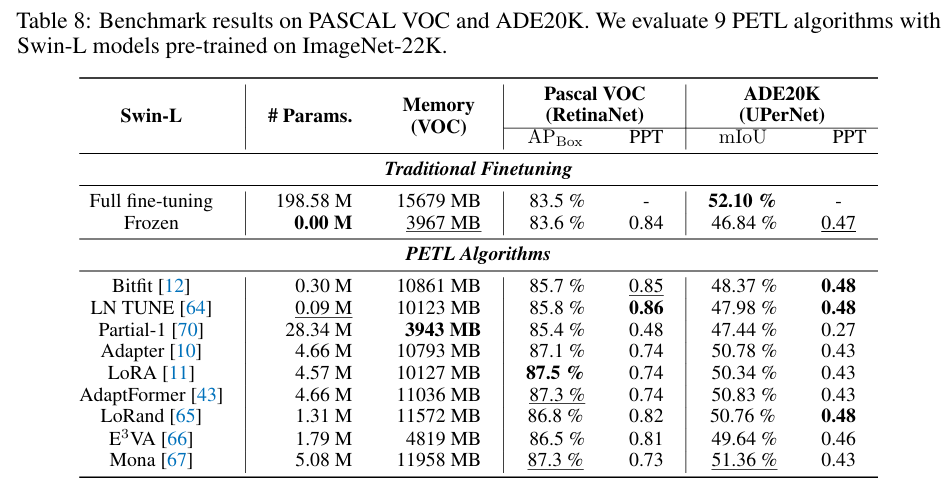
V-PETL Bench offers a diverse and challenging benchmark across 24 image recognition datasets, 3 video action recognition datasets, and 3 dense prediction datasets. By evaluating 25 standard PETL algorithms on these dataset, we obtain several interesting findings: 1) Existing PETL algorithms can achieve performance competitive with Full fine-tuning in most downstream tasks and perform significantly better than Full fine-tuning when the amount of data is insufficient, which indicates that it could be an effective alternative to Full fine-tuning; 2) Existing PETL algorithms demonstrate significant efficiency, where most algorithms only updated less than 1% of the number of the pre-trained model. Additionally, they lead to improved computation and memory efficiency while achieving better performance; 3) Directly applying PETL algorithms from the NLP domain to vision tasks without any specific design results in performance degradation compared to well-designed PETL algorithms tailored for the CV domain; 4) The data and task similarity between pre-training and downstream tasks plays a key role, with higher similarity leading to better results. Furthermore, no single PETL algorithm consistently outperforms all others across all tasks.
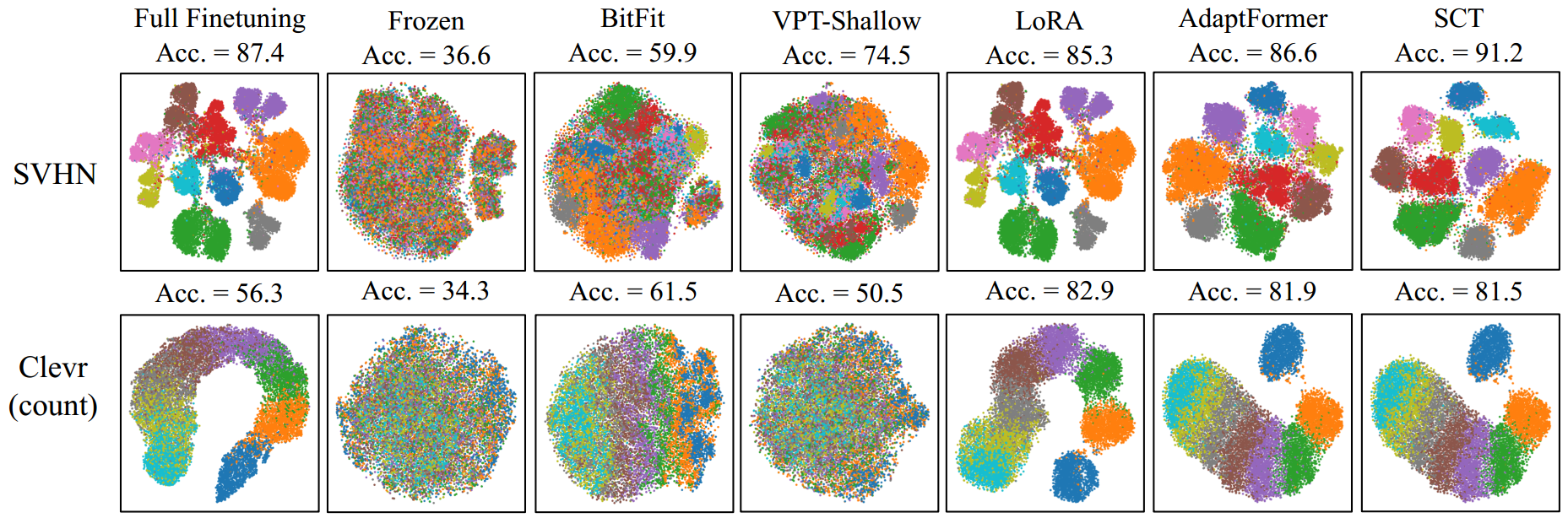
Visualization
V-PETL Bench offers t-SNE and attention map visualizations for better analysis of PETL algorithms.

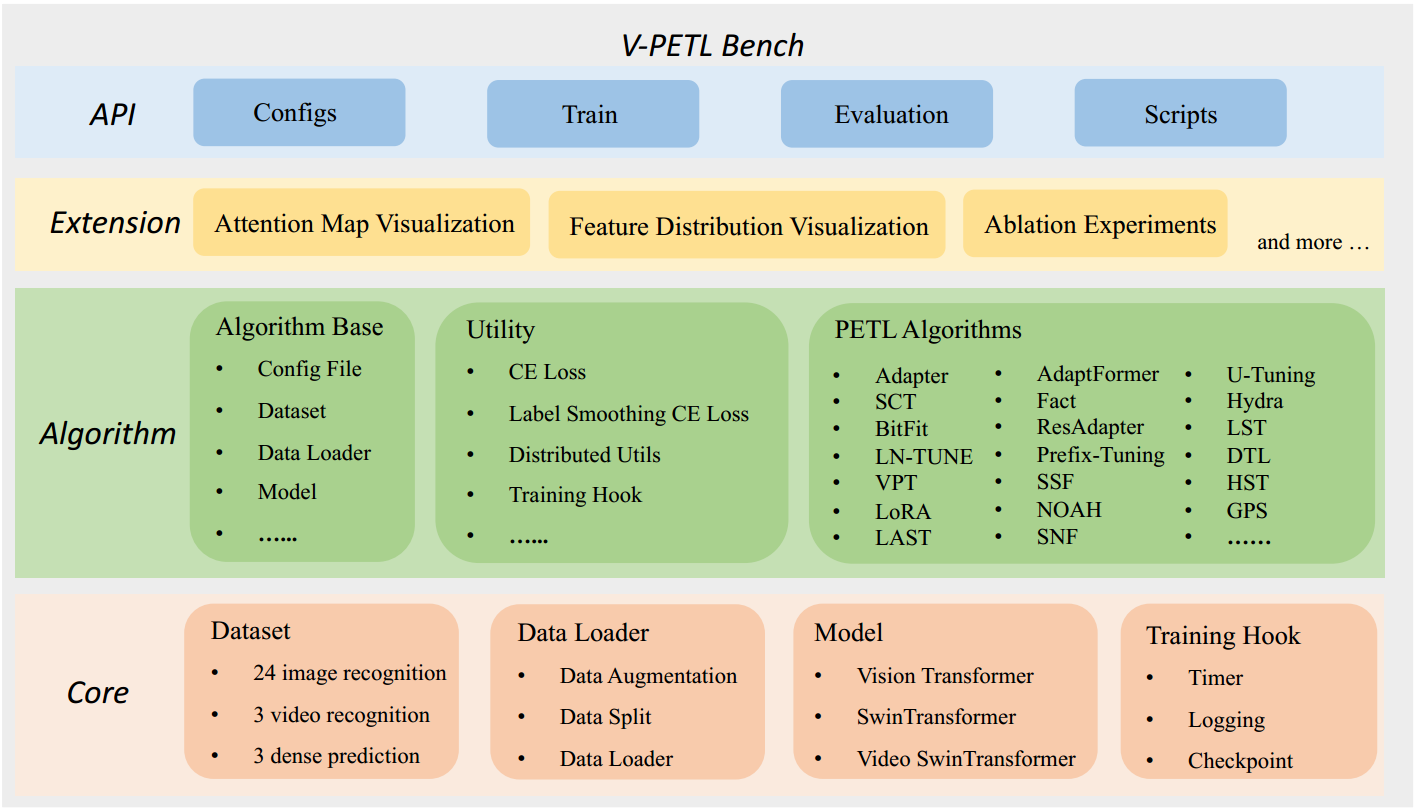
Codebase Structure
We provide an overview of the codebase structure of V-PETL Bench, which which is organized into four abstract layers. In the core layer, we implement the essential functions commonly used for training PETL algorithms. In the algorithm layer, we first implement the base class for PETL algorithms, which includes initializing the datasets, data loaders, and models from the core layer. The extension layer is dedicated to advancing the core PETL algorithms for visual analysis. We encapsulate the core functions and algorithms within the API layer, creating a user-friendly interface for individuals from diverse backgrounds who are interested in applying PETL algorithms to new applications.